Data Processing#
The Data Processing panel enables dataset preprocessing, including imputation, binning, encoding, scaling, splitting, and sampling. This guide follows a step-by-step workflow, integrating feature descriptions within each phase.
Initialize the Panel#
To create and initialize the Data Processing panel, use:
# Load the Experiment and preprocess the dataset
from modeva import Experiment
exp = Experiment(name='Demo-SimuCredit')
exp.data_process()
Workflow#
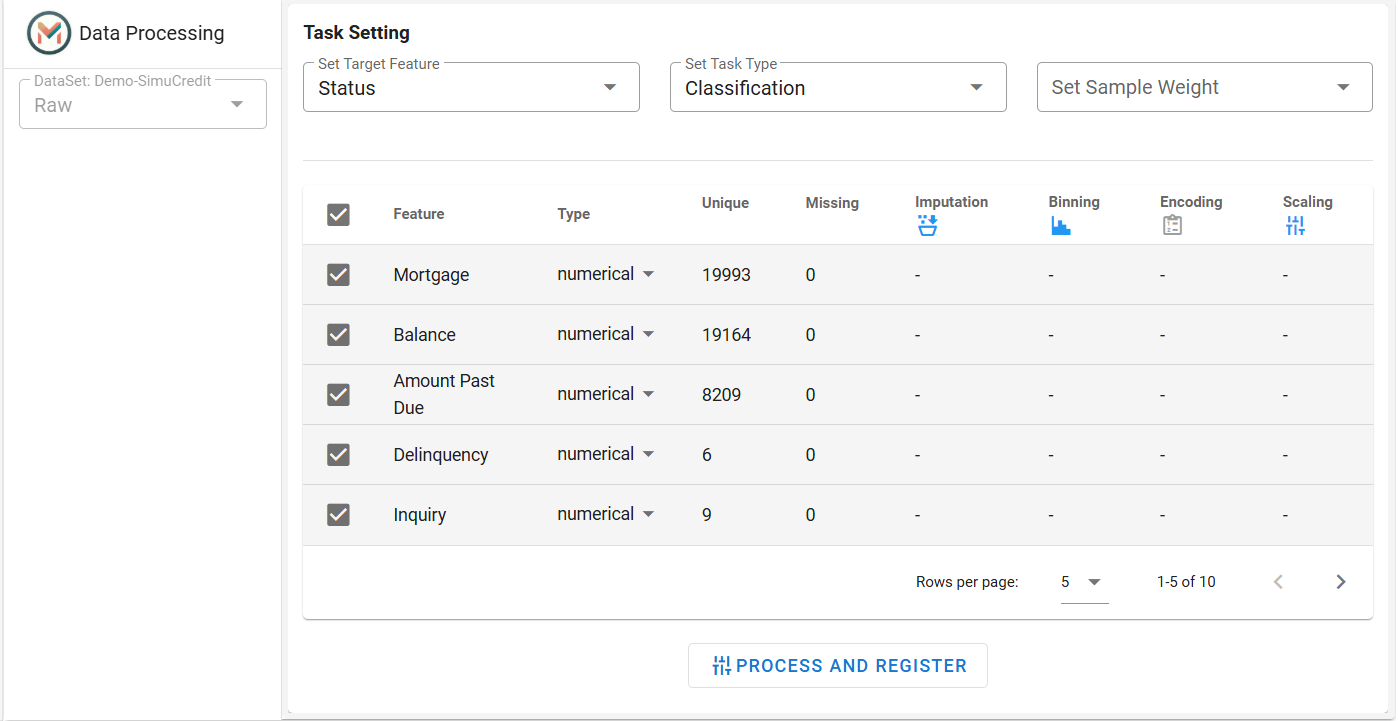
Step 1: Select variables and global settings#
The dataset from the dropdown for processing is automatically selected based on the raw dataset of the experiment (e.g.,
Demo-SimuCredit).Set Target Feature: Select the dependent variable (default: last column).
Set Task Type: The default task type is automatically detected (Regression or Classification).
Set Sample Weight (Optional): Choose a weight feature for model training.
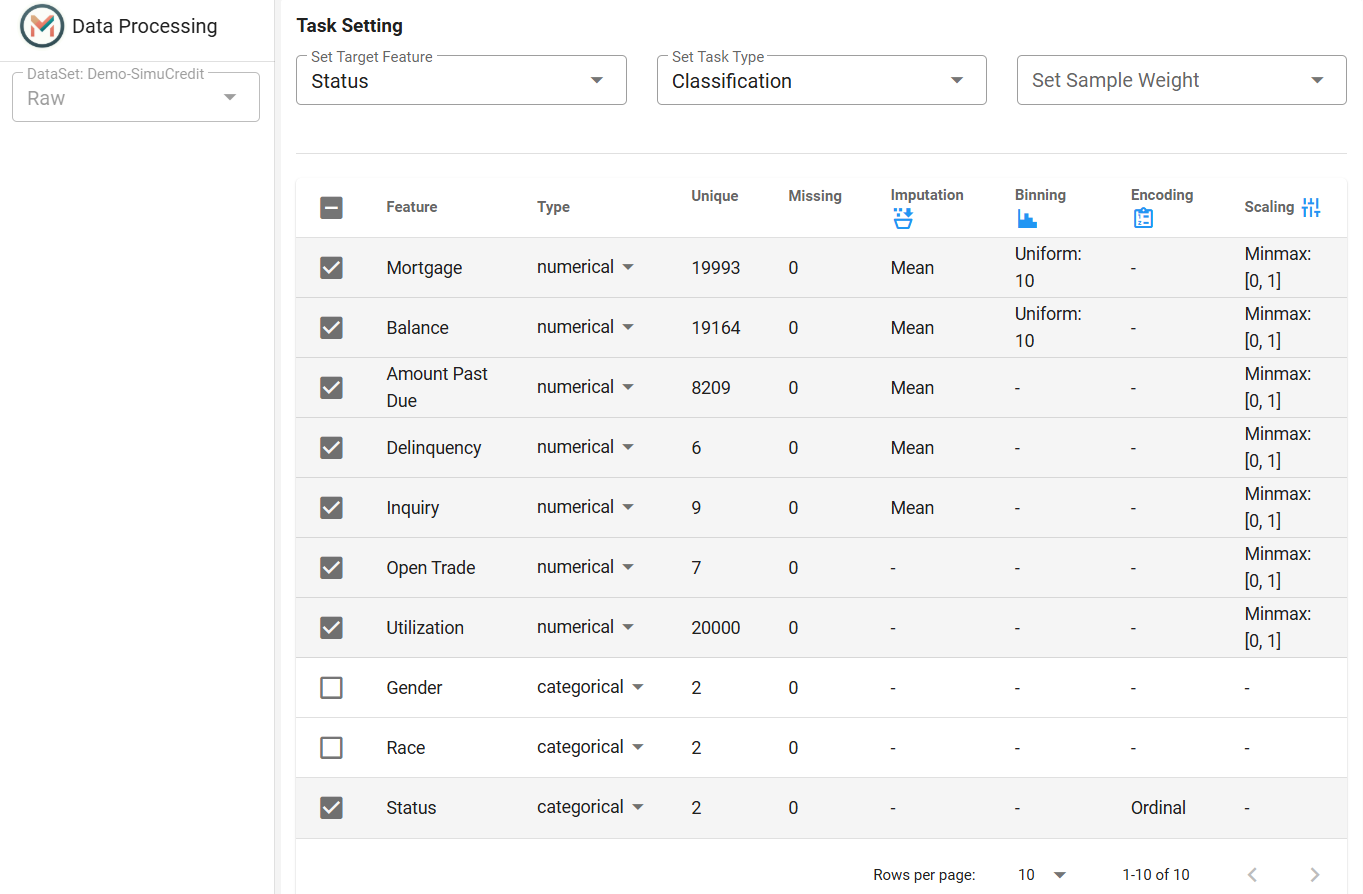
The Feature Table displays dataset attributes: Feature Name, Type, Unique Values, Missing Values, Preprocessing Steps.
Check the boxes
 next to the features to select features for processing and modeling.
next to the features to select features for processing and modeling.
Step 2: Process Features#
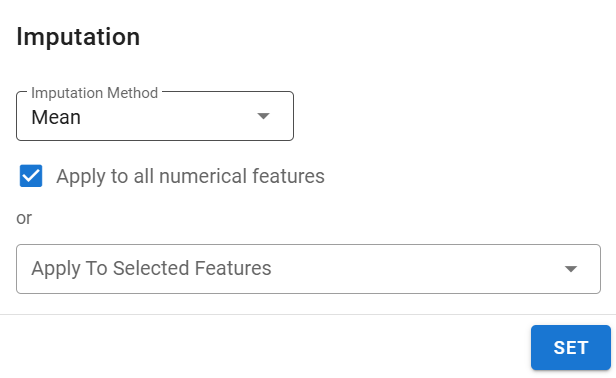
Imputation:
Click the column header Imputation to open the imputation settings.
Choose a method: Mean, Median, Most Frequent, or Const value (e.g., 0).
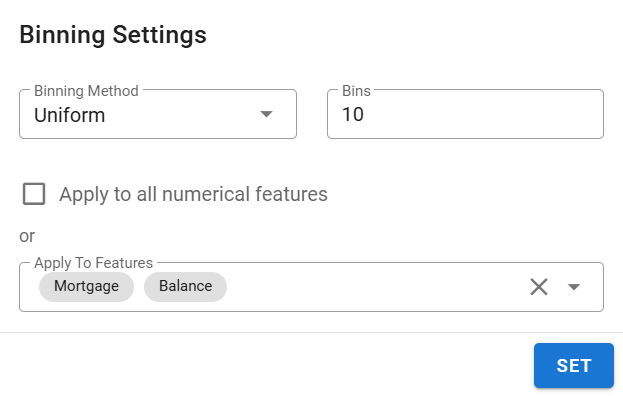
Binning (Numerical Features Only):
Click the column header Binning to open the binning settings.
Choose a method: Uniform or Quantile.
Set the number of bins (e.g., 10 for quartiles).
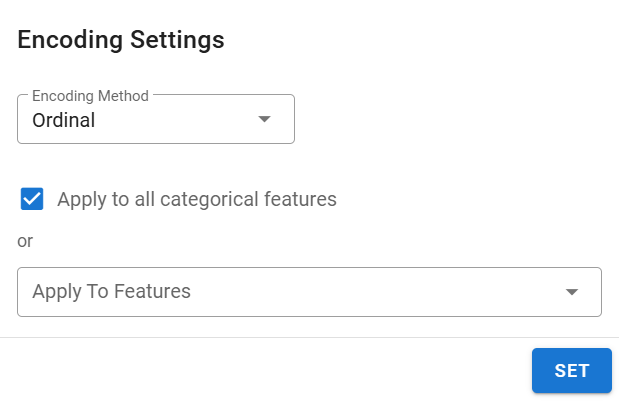
Encoding (Categorical Features Only):
Click the column header Encoding to open the encoding settings.
Select encoding method from Onehot or Ordinal encoding.
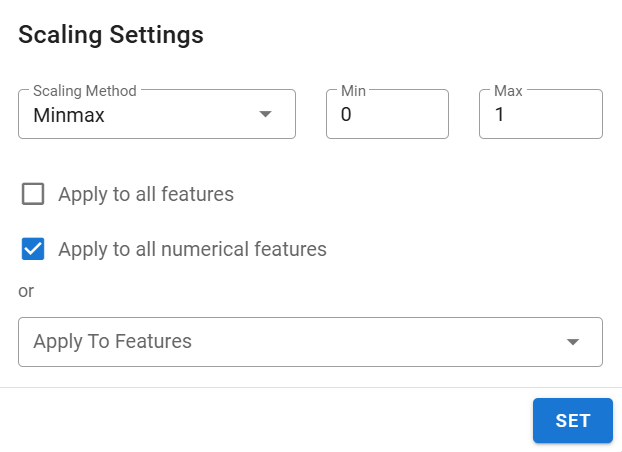
Scaling:
Click the column header Scaling to open the scaling settings.
Normalize values using Standard or MinMax with a custom range.
After processing settings, the Feature Table displays the applied preprocessing steps for each feature.
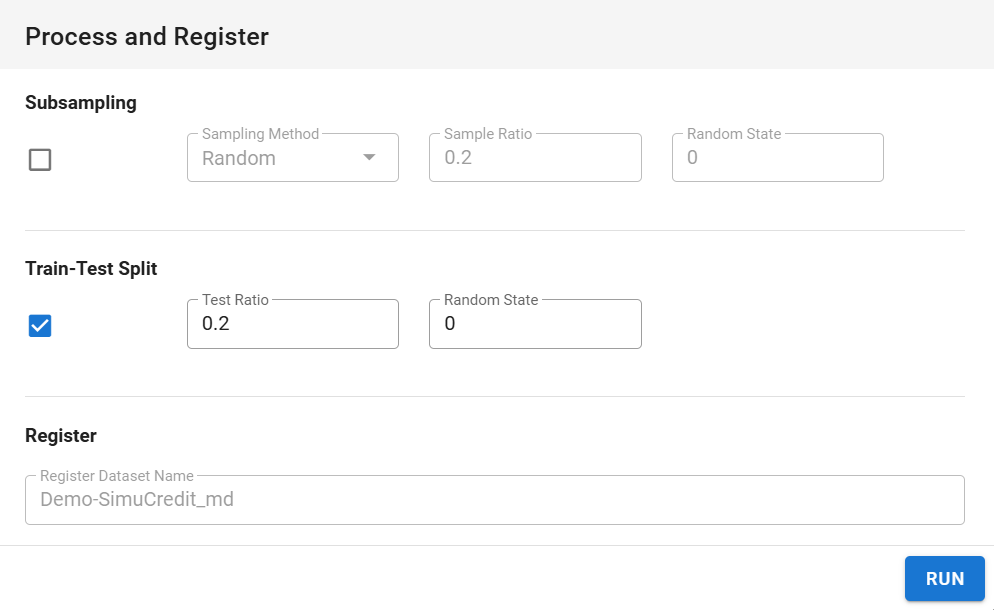
Step 3: Splitting, Sampling & Registering#
Click Process & Register to finalize preprocessing.
Sampling:
Click the checkbox
next to sampling settings if you want to apply sampling.Choose a method: Random.
Set the proportion of data to sample (e.g., 0.1 for 10% of data).
Set Random State for reproducibility (default: 0).
Splitting:
Set Test Ratio (e.g., 0.2 for 20% test data).
Set Random State for reproducibility (default: 0).
Register Dataset:
Click the Run button to process and register the dataset. The name of the processed dataset is locked to the original dataset name with a suffix (e.g., Demo-SimuCredit_md).
The Data Processing panel simplifies dataset preparation for machine learning. By following this guide, you can efficiently preprocess data for predictive modeling tasks. For more information, refer to the Data Basic Operation.